
Christian-Emil Ore (University of Oslo)
However, the hypertext feature of the Web makes it also well-suited as the basis for distributed multidisciplinary information systems where the nodes (the sites) are (a publication of) scholarly work. The information in a node can link information in other nodes both in a hypertext manner but also in a more batch or data base query like manner. This usage of the Web/Internet seems to be somewhat under-utilised. One may say that it is more common to publish one's work on the Web than to put the Web into one's work.
In this paper I will describe how three central Norwegian textual resources much used by archaeologists, historians, philologists and historically oriented linguists were published on the Web and show how we have tried to utilise the information in the texts to make them into an integrated part of the Web. One of the resources (a place name registry) traditionally (and manually) has been used as an index or link between the two others (archaeological acquisition catalogues and a collection of medieval charters or diplomas). With all the three sources were electronically available there is tempting to try to shortcut the place name link and present a new set of direct connections. This may be sound, but not in all cases. I will discuss some problems connected to making a real interconnection of digital resource for the humanists using for example the Internet, real in the sense that the information in some resources can be used to find connections between sets of information in others in an automated way.
As examples I will, as mentioned above, use resources based on medieval texts, on a place name study and on archaeological acquisitions reports all made electronically available by The National Documentation Project of Norway. This was a co-operative project undertaken by Faculties of Art at four Norwegian universities in the period 1992-1997. The main purpose of the project was to convert information from paper-based archives (manuscripts, acquisition catalogues, place name collection, etc.), to electronically readable media in order to make the archives more accessible. The project has been working with what can be called the "collection departments", such as the Department of Lexicography, the Department of Place Name Studies, and the university museums with archaeological and numismatic collections. The objective has been to create a national multidisciplinary information system combining material from all Norwegian universities. The system is based on printed material, published during the last 170 years, on unpublished card archives, and on existing databases (lexical databases and archaeological databases over sites and monuments). The potential inherent in the combination of different sources is especially useful to synthesising disciplines like archaeology and history. The project and its sub projects are described in more detail in Ore 1994 and the projects homepages (see The Documentation project 1998).
Figur 1 Facsimile from a typical page in Diplomatarium Norvegicum
<DIPLOMA ID="03734"> <INGRESS><NAME>Jon</NAME> Prest paa Ullinshof og hans Vicarius kundgjöre, at <NAME>Askel Halvardssön</NAME><L>stadfæstede sin Hustrus <NAME>Thora Eyvindsdatters</NAME> Salg af 4 Örtogsbol hadsk <L>(dvs: efter Hadafylkes Regning) i nedre Mo i Röyse paa Ringerige.</INGRESS> <SOURCE>Efter Orig. p. Perg. i Dipl. Arn. Magn. fasc. 64. No. 13. 1ste Segl vedhænger.</SOURCE> <NR>261.</NR><DATE YMD="13420303">3 Marts 1342.</DATE><PLACE>Lautin.</PLACE> <TEXT><LANGUAGE>gammelnorsk</LANGUAGE>Ollum monnum þæim sæm þetta bref sea eðr hœyra sændæ<L>Jon prester a Wllinshofue Joar prester uicarius þess sama stadar q. g.<L>ok sina mitt gerom yðr kunnightt at mitt warom j hia a Lautini a<L>pallmsunnu æptæn a þridiæ are ok tythugta rikis Maghnusar kononghs<L> ok soom er þau helldo handum soman Askiæll Hallwardz sson ok þoræ<L>Æiwindar dotter husprœyiæ hans samþyktti þa Askiæll fyrnæmder salu<L>þa er þoræ hafde sælltt j nedræ gardenom a Moe iiii œrttoghær boll<L>hatdz er lighær a Rœysi a Ringhæriki ok till sanyndæ sættum mitt<L>okor jnsigli firir þetta bref er gort war a dæghi ok are sæm fyr<L>sæghir.</TEXT></TEXT></DIPLOMA>
Figur 2 SGML-encoded version of the printed diploma
Diplomatarium Norvegicum consists of 22 volumes of printed transcripts of medieval diplomas concerning Norway in the middle ages. The texts are mostly written in Old Norse, Latin, Danish and German. The first volume was published in 1847 and work is still in progress with volume 23. The quality of the transcriptions varies and reflects the accepted standard of their time. In the printed edition, each diploma has a (tentative) date and place of issue together with some archival information of the original (now mostly outdated) and a short summary written in modern Danish or Norwegian. The Documentation Project has converted the complete printed Diplomatarium Norvegicum together with a set of new transcriptions of the Old Norse diplomas until 1302 are converted into an electronic text with SGML mark up. As an addendum to the Diplomatarium there now exists a six volume collection of new summaries and source information called Regesta Norvegica, all in electronic form.
In the late 19th century a new and complete land registry was compiled in Norway. A central member of the land register commission was the Norwegian philologist and archaeologist Oluf Rygh. On the basis of his work in the commission, Rygh started to publish a complete catalogue over the names of the main Norwegian farms (45 000 in 1886). For each farm the name is given together with its pronunciation, etymology and reported any variants in an impressive list of historical sources. The editing and publication of the catalogue was done over nearly 40 years and was completed long after Rygh's death. The etymological explanations are coloured by the desire of the national romantic movement to find the original name. In Norway at the turn of the century this meant an Old Norse name. In Southern Norway most names have an Old Norse origin. In Northern Norway there are lots of Norwegian sounding place names with a Saami origin. This fact and the still existing cultural conflict between the Norwegian and the Saami population imply that some parts of Rygh's work should be used with care. The huge number of references to name variants in the historical sources, however, makes the work very important for archaeologists, historians and people doing place-name studies. The entire catalogue has been converted by the Documentation Project into an electronic text with SGML mark up.
C 37269. Spearpoint of iron from Medieval time. L: 21.6cm, largest W:49mm, spear socket D: 33mm. W:ca.500gr. The spear has straight edges and angular shoulders. Cone shaped socket, R.526. Found in ploughed field, 100m SE of present farm house (1934-35) at BRÅTEN under JERDAL, KVINESDAL, VEST-AGDER. Gift from the owner of the farm Asbjørn Espeland. Acquired during surveying.
Figure 3. An entry from an acquisition catalogue translated into English.
Norway has five archaeological museums. They are situated in Oslo, Bergen, Trondheim, Tromsø and Stavanger. With the exception of Stavanger, all are university museums. Norway does not have a central museum, although the museum in Oslo tends to take a leading role, since being situated in the capital. All five museums started as private collections, and gradually developed into regional museums. The two oldest (Trondheim and Oslo) were established in the late 18th century and early 19th century. Each museum has a collection of items from its own district. Previously, however, the geographical division between the museums was not so rigid, resulting in the different museums having artefacts from other museum districts. Each of the Norwegian archaeological museums publish an annual report of the its new acquisitions. For each museum the series of catalogues constitutes the main inventory catalogue. The acquisition catalogues are quite verbose, see figure 1. The acquisition catalogues are also converted by the Documentation Project to electronic text with SGML mark up (figure 2).
<NRPAR><CATNR nrid="37269">C.37269. <ARTEFDATA><ARTEFACT>Spearpoint</ARTEFACT> of <MAT>iron</MAT> <SHARED>from <AGE>Medieval time</AGE>. <ARTEFDATA><MEAS>L: 21.6cm</MEAS>, <MEAS>largest W:49mm</MEAS>, <MEAS>spear socket D: 33mm</MEAS>. W:<WEIGHT>ca.500gr</WEIGHT>. <FORM>The spear has straight edges and angular shoulders. Cone shaped socket, <LITREF>R.<FIGNR>526</FIGNR> </LITREF> </FORM>. <SHARED>Found in ploughed field, 100m SE of present farm house (1934-35) at <FINDLOC><FARM>BRÅTEN under <FNAME>JERDAL</FNAME></FARM>,<MUNICIPALITY>KVINESDAL </MUNICIPALITY>, <COUNTY>VEST-AGDER</COUNTY></FINDLOC>. <ACQUI>Gift from the owner of the farm <FINDER>Asbjørn Espeland</FINDER>. Acquired during surveying.</ACQUI> </NRPAR>
Figure 4. The entry from figure 1 with SGML markup added.
Above I have described parts of the works done by the Documentation project in the fields of Old Norse and medieval history, place name studies and archaeology. The tasks alone have produced electronic texts with SGML mark up equivalent to 22 000, 6 000 and 20 000 pages of printed text respectively. In addition the data collection consists of several hundred other smaller and larger texts. Our system can be viewed as a library of such passive electronic texts. The users can "borrow" texts in a similar way as is possible, for example, in The Oxford Text Archives. This "library", and the rest of the system described below, is implemented as a combination of a relational database system (ORACLE) and a free-text system (OpenText) and has a HTTP-based World Wide Web (WWW) interface.
As figure 5 indicates, there are also links from the archaeological catalogues to the "Norwegian Farm Names" series. The links are implemented in the same way as described above. In this case, however, some filtering was required, and names and land registry numbers were adjusted since there have been many changes in the Norwegian orthography and land registries during the last hundred years.
The indicated links in the figure 5 are of different types. Links of the first type (from Norwegian Farm Names to Diplomatarium Norvegicum)are just electronic versions of explicit references made by the original author. In this case, we did not add information to the original text. Links of the second type was added by the editors of the electronic edition of the acquisition catalogues. Though they would, perhaps, have been welcomed by the original author(s), they represent new information added to the text.
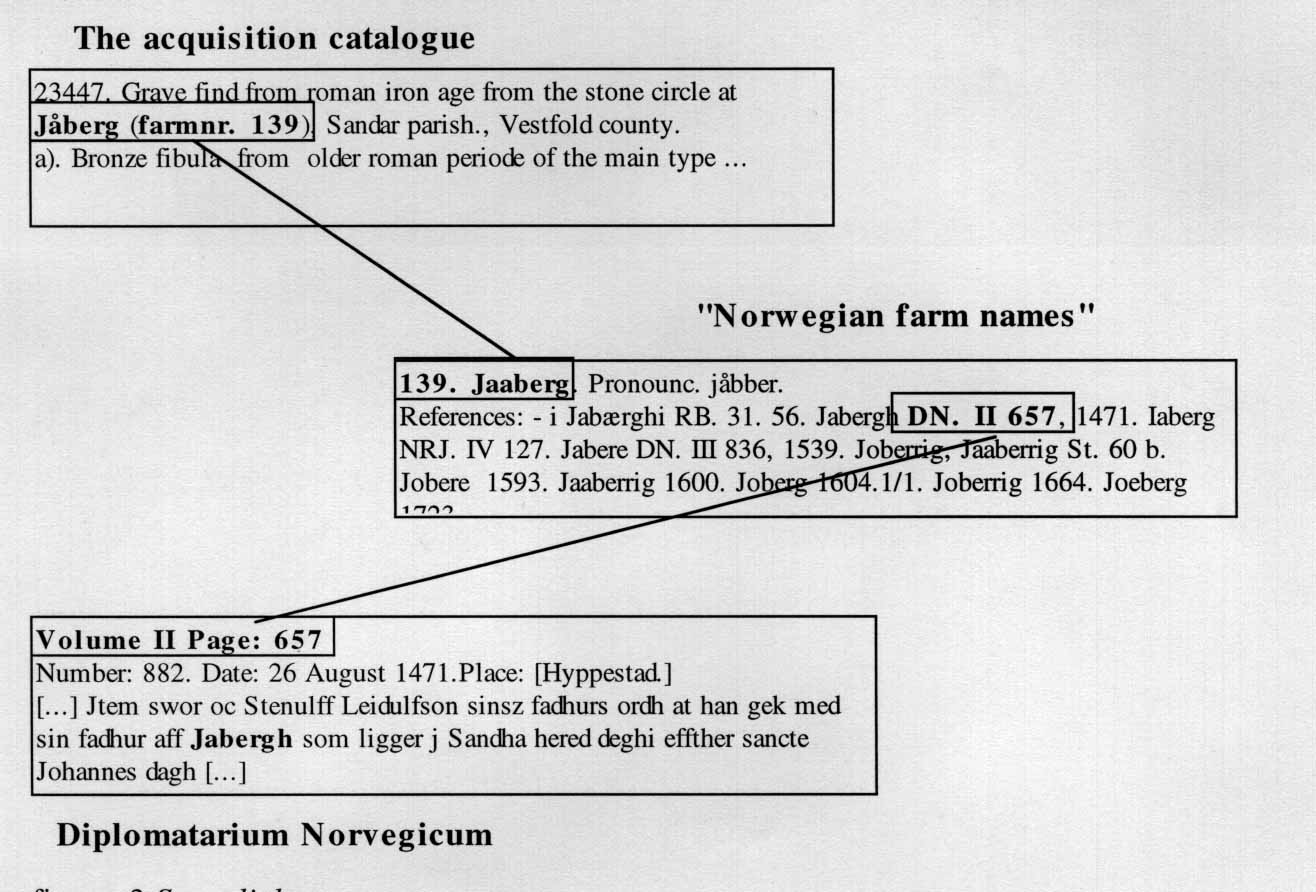
figure 5. Examples of some links.
The WWW interface and the implementation of text references as pointers to URLs, make the texts described above, an integrated part of the Web. Thus, with their references the good old "Norwegian Farm Names" study and the Diplomatarium Norvegicum have become part of the World Wide Web. In these days this may sound trivial. There are, however, not many scholarly works published on the Web and even fewer that are designed as an integrated part of the Web.
Some of the texts in the collections are originally meant to be surveys or catalogues (e.g. the acquisition catalogues). Other texts are treaties, appointments and other kinds of official documents (e.g. the medieval diplomas). The literary texts are written for different purposes. All texts are included in the system because they are used by scholars as a source of information. Sometimes the scholars are interested in the information the original author tried to communicate and sometimes they are not. The linguists use of the medieval diplomas as a source of information about Old Norse syntax is an example of the latter case.
When texts that were originally written as catalogues or a systematised collection of other texts (like Diplomatarium Norvegicum) are converted into data bases or supplied with SGML mark up we create explicitly or implicitly a data model of the world described in the texts. The archaeological reports, for example, refer to farm names and to administrative units like counties and parishes in Norway, while the diplomas are given a time and place of issue. The data model defines the possibilities and/or limitations regarding what kind of queries that can be made. The reliability of the information we get out of the database depends upon the quality of work of the creator of the original text. If we now try to interconnect the databases and their model worlds the resulting system can be more than its parts and this may or may not be a good thing. It is fine if we get new and correct information. However, in a badly designed system we may get answers that are wrong or only partly correct.
Consider for example, the subset of our databases consisting of the acquisition catalogues, farm name catalogue, and the Diplomatarium Norvegicum. In almost every entry in the archaeological catalogues the place of the find is identified by the county, parish and/or the farm name with its land-registry identification number. In most cases, it is possible to use the farm name catalogue to find the diplomas in the Diplomatarium Norvegicum mentioning the farm. By using the SGML mark up the system gives the user the chance to follow links from the archaeological reports via the farm name catalogue back to the diplomas. Figure 3 is such an example.
In the Documentation Project we implemented a 'bulk' query option enabling queries like "For all farms in the county of Vestfold with grave finds, find the diplomas mentioning the farms by using Oluf Rygh's 'Norwegian farm names'." If this query were done by separate queries, we first have to find all grave finds in the county of Vestfold. Then we would find the corresponding entries in 'Norwegian farm names' and make a list of the references to the Diplomatarium Norvegicum. Finally we would have had to find each of the diplomas. Even with the use of separate databases this is a time consuming (and tedious) piece of work. The search system does most of the work. It is extremely important, however, that the user either has the chance to select source(s) which should be used to establish the link between a farm mentioned in an archaeological report and a diploma from 1471 or be informed afterwards about the source(s) actually used. The result of a query like "For all farms in the county of Vestfold with grave finds, find the diplomas mentioning the farms" is not of much interest from a scientific point of view if there are no references as to how the results were deduced. In the example discussed here, it is not sound to hide the fact that the that "Norwegian Farm Names" study is the source.
Cultural Heritage Information Online (CHIO) http://www.cimi.org/projects/chio.html,1998
Delary P., and Landow G., (eds);Hypermedia and Literary Studies. The MIT Press, London 1991
Diplomatarium Norvegicum, Oldbreve til Kundskab om Norges indre og ydre Forhold, Sprog, Slægter, Sæder, Lovgivning og Rettergang i Middelalderen, (Ancient letters collected for the dissemination of knowlegde about internal and external affairs, Language, Families, Traditions, Law and Court Practice in Norway in the Middle ages) Vol 1-22, 1849-1990. Christiania/Oslo
Holmen, J. and Uleberg, E. 1996,The National Documentation Project of Norway - the Archaeological sub-project in Kamermans, H. og Fennema, K. (ed)s, Interfacing the past, CAA95. Leiden: University of Leiden.
Ore, C.-E.Making an information system for the Humanities Computers and the Humanities, Journal of the ACH, 1994
Robinson P. (ed); The Wife of Bath's Prologue Cambridge University Press, Cambridge 1996
Sperberg-McQueen, C.M. and Burnard, L. (eds) 1994: Guidelines for the Encoding and Interchange of Machine-Readable Texts (TEI P3). Chicago og Oxford:
Rygh, O. 1897-1936: Norske Gaardnavne(Norwegian Farm Names). Kristiania (Oslo)
Årbok(Yearbook) 1958-1959 1960: The Archaeological Museum, University of Oslo, Oslo